Improving Large Language Models with Concept-Aware Fine-Tuning
论文链接:https://www.arxiv.org/pdf/2506.07833
代码链接:https://github.com/michaelchen-lab/caft-llm
摘要
大语言模型(LLM)已成为现代人工智能的基石。然而,现有的逐 token 预测范式从根本上限制了它们形成连贯的高级概念的能力,使其成为实现类人理解和推理的关键障碍。以短语“ ribonucleic acid ”为例:LLM 首先会将其分解为 token,即人工文本片段(“rib”→“on”→……),然后按顺序学习每个 token,而不是将整个短语理解为一个统一的、连贯的语义实体。这种碎片化的表示阻碍了更深层次的概念理解,并最终阻碍了真正智能系统的开发。为此,我们提出了 Concept-Aware Fine-Tuning (CAFT),一种新的多 token 训练方法,它重新定义了 LLM 的微调方式。通过支持跨多个 token 的序列学习,该方法促进了更强大的概念感知学习。我们的实验表明,与传统的下一 token 微调方法相比,CAFT 在各种任务中均取得了显著的改进,包括文本摘要等传统应用以及从头蛋白质设计等特定领域应用。此前,多 token 预测只能在成本极高的预训练阶段实现;据我们所知,CAFT 是第一个将多 token 设置引入后训练阶段的方法,从而有效地将其优势普及到更广泛的从业者和研究人员群体中。最后,我们提出的方法出乎意料的有效性表明,它对机器学习研究领域具有更广泛的意义。所有代码和数据均可在 https://github.com/michaelchen-lab/caft-llm 获取。
1.介绍
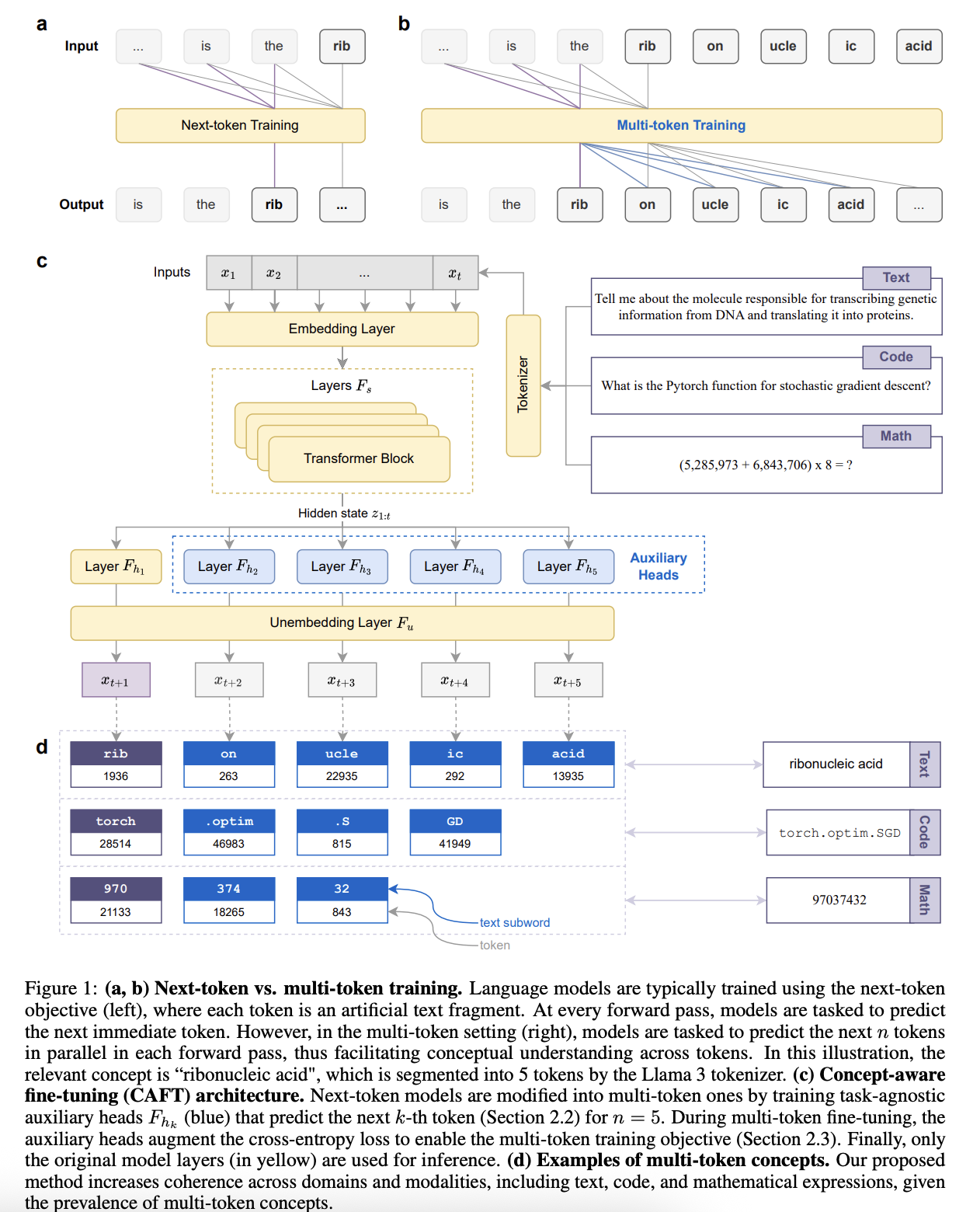
近年来,大语言模型(LLM)取得了巨大的进步。其成功很大程度上归功于高效的 LLM 开发流程。该流程可以概括如下:首先,在预训练阶段,模型在大规模无监督文本语料库上进行训练,以学习通用知识和语言理解能力。其次,在后训练阶段,模型在下游监督数据集上进行微调,以应对特定格式的各种任务,并通过多种技术防止模型出现危险行为。这些技术包括指令微调、基于人类反馈的强化学习(RLHF)等等。这种训练范式极大地推动了语言模型在人工智能研究和商业应用领域的增长。
重要的是,这种训练范式符合一个看似无可挑剔的训练目标:预测下一个 token。首先,使用 tokenizer 算法(最常用的是字节对编码 (BPE))创建一个 token(或文本片段)词表,该算法根据 token/子词在训练语料库中的出现频率生成 word/subword token。使用该词表对文本进行 tokenizer 后,将生成的 token 输入模型,以自回归的方式预测下一个 token。例如,如图 1(a,b) 所示,如果 Llama 3 模型的任务是预测给定问题中的“ribonucleic acid”,则首先将该短语分解(即 tokenizer)为 rib、on、ucle、ic 和 acid。然后,训练模型在每次前向传播中依次预测单个 token,从 rib 开始。
然而,这种训练目标并非最优:token 是人为划分的文本片段,并不代表连贯的概念或实体。在每次前向传播过程中,模型都无法访问后续的 token。例如,当预测“rib”是 “ribonucleic acid” 的一部分时,后面的 “-onucleic acid” 部分就被隐藏了。直观地说,孤立地学习一个属于更大概念的单个 token,无法捕捉到实际的潜在信息。越来越多的关于 tokenizer 对语言模型性能影响的文献支持这一论断。压缩率更高的 tokenizer (即能够将文本离散化为更长的词和子词)比压缩率更低的 tokenizer 能带来更好的模型性能。此外,tokenizer 的具体实现方式会影响数字和数学表达式的分割方式,最终会对算术能力产生不利影响。训练模型预测下一个 token 会阻碍其学习过程。
相反,模型应该被训练来预测概念,这些概念通常跨越多个 token,如图 1d 所示。基于此,一些利用多 token 预测的方法已被提出。具体来说,在训练语料库的每个位置,模型被训练来使用 n 个输出头预测接下来的 n 个 token。然而,这些方法仅限于预训练阶段,导致成本过高且效果不佳。首先,预训练阶段的计算成本比后训练阶段高出几个数量级,使得现有的多 token 方法除了少数资源充足的实验室外,几乎无法应用。其次,预训练阶段 teacher 模型通用知识和语言建模技能,而后训练阶段学习特定且相关的技能。因此,现有方法无法充分学习特定领域的多 token 概念:与下游任务中对应的下一个 token 方法相比,它们仅表现出增量式的提升。
人们自然会预期多 token 预测应该应用于微调阶段。然而,据我们所知,目前这方面的研究尚未取得成功,研究发现使用多 token 预测进行微调会导致性能相似甚至更差。将多 token 设置融入后训练阶段极具挑战性,因为多 token 设置代表着分布的显著变化。鉴于后训练阶段远短于前训练阶段,模型无法适应,从而导致性能下降。
为此,我们提出了 Concept-Aware Fine-Tuning (CAFT),一种用于预测下一个 token 模型的多 token 微调方法。首先,我们使用指令-微调混合方法训练辅助头,用于预测下一个 token 之后的 token 位置,其中真实响应由模型自身自提炼而来。我们为一系列流行的开源模型提供了训练好的、与任务无关的辅助头,使用户能够专注于特定任务的多 token 模型(MTP)微调,如图 1c 所示。在基础模型上进行完全微调或低秩自适应(LoRA)微调的基础上,我们添加了辅助头和多 token 损失函数。
我们通过实验证明了 CAFT 的有效性和适用性,涵盖了包括文本摘要等传统领域和从头蛋白质设计等特定领域在内的多个领域。其性能优于基于下一个 token 的完整微调和 LoRA 微调方法。尽管计算成本仅为现有 MTP 预训练方法的几分之一,但其性能提升幅度却与之相当甚至更高。此外,我们发现 CAFT LoRA 通常优于基于下一个 token 的完整微调,这表明模型在多 token 环境下学习效率更高。在多 token 预测优势显著的场景下,模型性能可以实现数倍提升。
重要的是,CAFT 对科学界具有重要意义。首先,通过将多 token 预测引入后训练阶段,我们的方法使更广泛的实践者和研究人员能够受益于多 token 预测(MTP)。这为未来在这个新兴领域的研究奠定了基础。其次,语言模型(LLM)能否预测下一个 token 之后的内容仍然是一个备受争议的问题。CAFT 的超高效率表明,这些模型无法充分学习和预测下一个 token 之前的内容;明确的多 token 目标更为有效。我们的实证研究是理解语言模型内部机制的关键一步。
2.Concept-Aware Fine-Tuning (CAFT)
首先训练辅助头,以便于进行多 token 微调,我们将在第 2.2 节中描述。对于给定的模型,辅助头只需训练一次,并且可以由第三方提供,因此从业者只需专注于下一步:针对特定任务的多 token 微调,这将在第 2.3 节中描述。为了更好地说明多 token 设置,我们首先简要介绍标准的下一个 token 训练方法。
2.1 Background on Next-token Prediction
传统上,语言模型使用自回归方法在大型文本语料库上进行训练,训练任务为下一个 token 预测,如图 1a 所示。给定输入 ,模型的任务是预测 ,目标是最小化以下交叉熵损失:
其中 是位置 处的真实 token。这一核心目标在预训练和微调中都占据主导地位。在这项工作中,我们重新调整了这一普遍存在的训练目标,使其预测接下来的 n 个 token,如图 1b 所示。
The challenge of multi-token fine-tuning。将多 token 设置融入后训练阶段并非新思路;然而,现有的尝试均未取得成功。例如,Gloeckle et al. (2024) 发现,即使对于在多 token 设置下预训练的模型,下一 token 预测在微调阶段的表现也更佳!简单地将多 token 预训练方法应用于下一 token 模型的微调会带来几个问题:首先,引入多 token 目标函数会带来分布的剧烈变化,模型通常无法从中恢复,导致性能甚至不如基础模型。其次,由于辅助头的损失自然更高(因为它们位于 token 更远的位置),模型往往会为了优化辅助头的损失而牺牲 损失,而 损失才是推理阶段最终重要的因素。最后,训练后阶段比预训练阶段短得多;使用现有方法,模型没有足够的计算资源来充分利用多 token 设置的优势。
我们提出的方法 CAFT 引入了一系列新的技术和应用,旨在解决这些以前未解决的挑战,使其成为第一个实现多 token 微调的方法。
2.2 Setting the stage: Training auxiliary heads
在将 CAFT 应用于下一个 token 模型之前,必须先对其进行调整,使其能够一次性预测 n 个未来的 token。因此,需要训练一些辅助头,用于预测第 k 个 token。重要的是,这些辅助头与任务无关,可以用于各种下游微调任务。
添加 个辅助头来预测接下来的 n 个 token。该架构包含:(i) 一个独立的隐藏层 ,其权重初始化与原始模型的最后一个隐藏层 的权重相同;(ii) 一个与原始模型共享的非嵌入层 。在图 1c 中, 层以蓝色显示, 层位于其下方。由于现有 LLM 的词表过大,因此共享 层。给定 token 上下文 ,每个头的输入是来自原始模型共享的 Transformer 层 (不包括 )的隐藏表示 。形式上,为了输出 ,第 个头定义为:
对于 的情况,使用完全微调来训练层 ,而所有其他层(包括非嵌入层 )均被冻结。这既可以防止层 的性能下降,又能同时降低计算成本。接下来 n 个未来 token 的交叉熵损失为:
其中 是位置 处的真实 token, 是一个几何衰减因子,用于降低辅助头在后续 token 位置的损失。由于未来 token 位置的固有不确定性,位置越远,损失也越大。 调整相应的损失,以促进更稳定的训练。
由于大多数开源模型缺乏原始训练方案,我们构建了一个包含 10 万个样本的指令微调数据集,该数据集来源于 ShareGPT 数据集和 Tulu 3 SFT 混合数据集。它涵盖了广泛的任务,以确保辅助头与任务无关;完整的任务分类见表 X。重要的是,为了匹配第一个(原始)头的输出分布,该数据集的真实答案是从原始头 中自行提取的。换句话说,只有数据集中的问题来自外部。
2.3 Concept-aware fine-tuning using auxiliary heads
在添加根据公式 2 训练和定义的辅助头之后,即可执行特定任务的 CAFT 算法。通常,仅对原始模型中的参数进行微调。例如,对于 LoRA 微调,除 的 层(以减少内存占用)和非嵌入层 (以提高训练稳定性)之外的所有层都会被调整。理论上,除了完整微调和 LoRA 微调之外,还可以使用其他微调方法,但这超出了本文的研究范围。
最终,主要目标是最小化第一个头的 损失,因为只有第一个头用于推理;所有后续头的损失都只是辅助性的。基于此,CAFT 的交叉熵损失计算如下:
其中, 调整所有辅助头损失的权重, 调整它们在训练迭代过程中的权重变化。实践中,我们发现模型往往会优先优化辅助损失,而牺牲第一个头的损失 (),因为前者通常较大。设定 () 可以确保训练仍然主要关注 (),而采用衰减的正弦调度用于 可以让模型在初期更加关注辅助损失,但最终仍然优化 ()。
重要的是,多 token(multi-token)设置的有效性与辅助头对给定任务的适应性直接相关。按照第 2.2 节所述的方法,这些头在一般对话、编程和数学任务上都表现出良好的效果。然而,对于具有多样且不可预测 token 的任务(例如故事写作)或具有未知格式的任务(例如蛋白质序列),最好按照公式 3 中的方式在该任务的训练集上对辅助头进行一次微调。计算开销极小,但能显著提升 CAFT 的效果。
训练完成后,辅助头会被丢弃,仅保留基础模型。因此,在模型推理时无需任何额外的计算成本或代码修改。
2.4 Practical Implementation

概念感知微调(Concept-aware fine-tuning)几乎可在所有语言模型上轻松实现。实际中,流行模型的辅助头将由各研究实验室和模型提供方训练并开源。基于行业标准的 Transformers 库,实践者只需在自己的微调脚本中增加几行代码,并使用我们开源的库 caft。图 2a 展示了一个示例实现。
给实践者的一些建议如下:首先,最好同时监控公式 3 中定义的 () 和 ()(不含 或 )。我们应预期:(i) () 会随着 epoch 的增加而降低,这表明模型已优化辅助损失;并且 (ii) () 的最终值通常低于传统微调的结果,这说明多 token 目标是有益的。其次,在实践中,我们发现当 () 时,辅助头的效果过于不稳定,此时应采用前述的头部微调策略。